infant eye-tracking coding machine
Automating Thousands of Frames with Infant Eye-Tracking Coding Machine

Infant Event Representations Original
YouTube Video of original
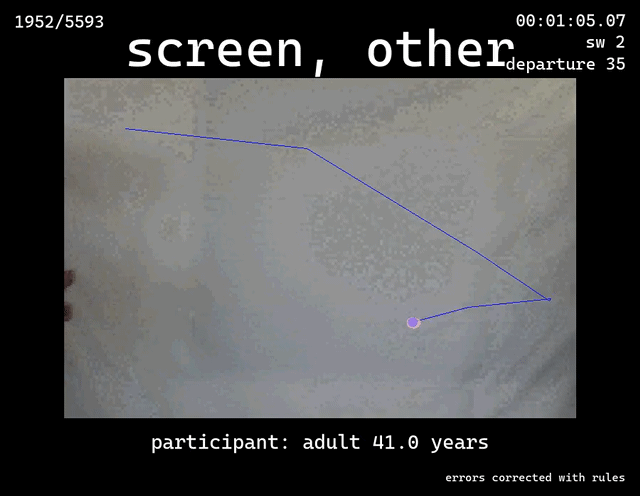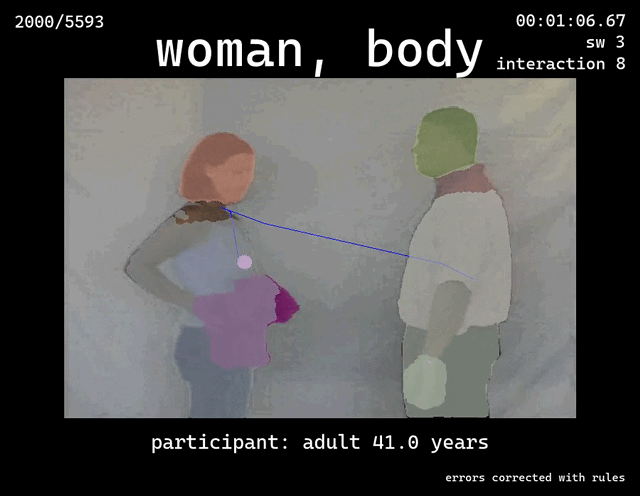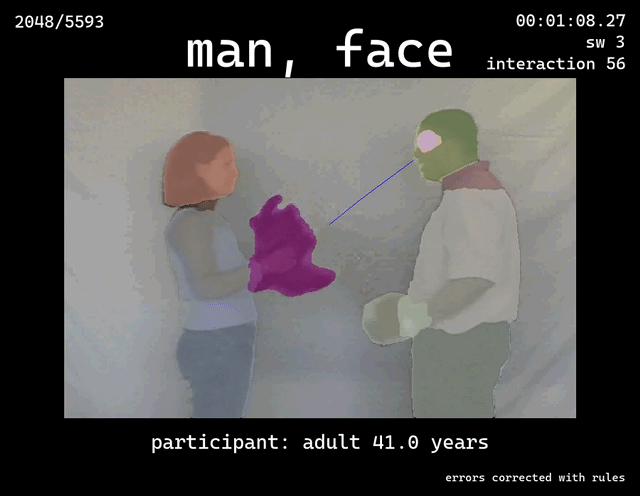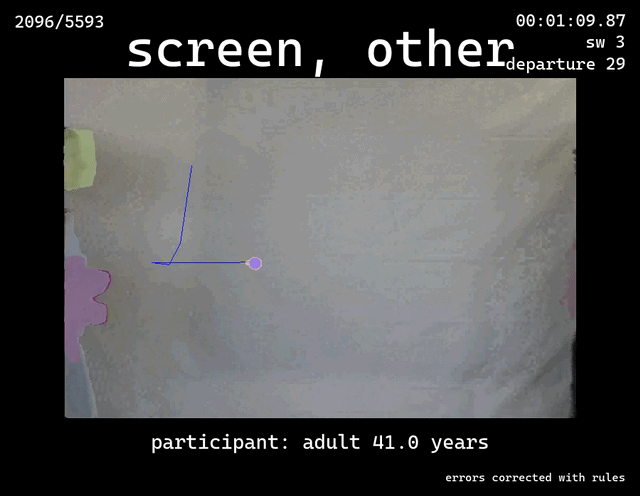
Infant Event Representations V2
YouTube Video of V2
participant datasheet, 1 of 72
We begin with ~75 participant video files (~300 minutes / 540k frames) that would take many hours to code by hand. This ML-powered and rule-based verified workflow automates the process outputting labeled video files and accompanying datasheets.
How the Project Works
Video Preprocessing:
Standardize and extract frames with 0_1024resizer.py, ensuring all later steps handle a consistent format.
Detection & Segmentation:
Run 1_inference_restore.py to detect relevant objects (blue dot, toys, faces, hands, etc.). Store both numeric data (JSON) and annotated images.
Classification:
Use 2_video_classify.py to place frames into broad event categories. This organizes each frame from a simple object detection level to a higher-level event timeline.
Refinement:
3_correct_event_labels.py ensures event data remains consistent over entire segments or trials.
Quality Check:
4_content_checker.py confirms that you haven’t lost or missed any frames during the pipeline.
Frame-by-Frame Data Assembly:
5_datasheet.py gathers “What/Where” details from the detection JSON, producing a readable CSV.
Merging & Consolidation:
6_consolidation.py unites classification results with the datasheet data, adding participant info (infant/adult, age).
Final Corrections:
7_csv_correction.py applies known fixes to any mislabeled events.
Video Rendering:
Lastly, 8_movie.py creates an MP4 with text overlays drawn from the final CSV, giving you a frame-accurate movie where each moment includes relevant annotations.
more detailed information
Project Objective
The overall goal is to transform raw video files from eye-tracking studies into organized data and final annotated videos. This method is an alternative to coding with traditional software like ELAN or Datavyu.
In these processed videos, each frame is labeled with important metadata (e.g., what the participant is looking at) and compiled into a coherent movie that showcases both the visual scene and the extracted information. By following a systematic set of scripts, you end up with:
- Frames correctly sized and padded.
- Object detections and segmentations (where the blue dot overlaps with certain objects or body parts).
- Classification of events.
- Refined corrections of mislabeled data.
- Consolidated data sheets that merge everything into a single comprehensive source of truth.
- A final video that visually presents each frame along with textual overlays drawn from the processed CSV data.
Below is a step-by-step look at each script in the workflow:
1) 0_1024resizer.py
Purpose: Extract frames from the original video files and pad them into a standardized 1024×1024 resolution.
Process:
- Scans through the target directory for video files (.avi).
- Uses ffmpeg to output sequential frames (e.g., frame_0001.png, frame_0002.png, etc.).
- Places these frames in a subfolder named
1024x1024_frames.
Outcome: The script ensures every video frame has consistent dimensions, which helps subsequent processes handle the images uniformly.
2) 1_inference_restore.py
Purpose: Use an object detection model (YOLO) and a segmentation model (SAM2) to detect items of interest (e.g., body parts, toys, the blue dot) on each frame.
Process:
- Searches for all
1024x1024_framesfolders. - For each frame, runs YOLO to get bounding boxes, then refines masks using SAM2.
- Saves results (segmentation masks, bounding box data) in a
detectionsfolder underinference_output. It also creates annotated images invisual_outputs(e.g.,frame_0001_annotated.jpg).
Outcome: Each frame ends up with JSON files containing detected objects and their segmentation masks, plus a visual representation of those detections for easy inspection.
3) 2_video_classify.py
Purpose: Perform an event classification step (e.g., labeling frames with broad categories like “green_dot,” “f,” “gw,” etc.).
Process:
- Scans for
_framesfolders and creates or resumes aclassification-run-XXdirectory. - Sends each frame to a classification model, saving results as JSON in
classification-run-XX/detectionsand a summary CSV nameddetections_summary.csv. - Organizes frames into labeled events and updates a CSV that tracks which frames are classified as which event.
Outcome: Produces a classification-run folder containing JSON files and a summary CSV that indicates high-level event labels for each frame (independent of the segmentation data).
4) 3_correct_event_labels.py
Purpose: Refine or “correct” the labeled frames by applying certain grouping rules and definitions for events (e.g., merging or splitting segments, ensuring consistency between repeated frames).
Process:
- Reads each
detections_summary.csvfrom aclassification-run-XXfolder. - Cleans up or merges consecutive event segments, assigns trials and chapters (e.g., approach, interaction, departure).
- Outputs a corrected CSV named
detections_summary_corrected.csv.
Outcome: Ensures event labels are cohesive over time (for instance, frames between two “green_dot” events might all be re-labeled with a single standardized event name).
5) 4_content_checker.py
Purpose: Verify that each participant’s folder has a matching number of frames and detection outputs (i.e., confirm that the pipeline remains consistent throughout).
Process:
- Recursively scans participant directories for
1024x1024_frames,classification-run-xx/detections, andinference_output/detections/visual_outputs. - Compares how many files exist in each relevant subfolder.
- Logs mismatches or missing data.
Outcome: Allows you to catch incomplete or inconsistent processing steps before moving on.
6) 5_datasheet.py
Purpose: Create a combined “datasheet” CSV from the detection JSON files in inference_output/detections, focusing on “What” (toy, body part, screen) and “Where” (the location or class).
Process:
- Reads each detection JSON, looks specifically for “blue_dot” masks and the objects they overlap.
- Compiles the frame number, detection classes, and overlap results into a single CSV.
- Saves
datasheet-[participant_id].csvin a newdatasheetfolder, listing the frame-by-frame “What” and “Where.”
Outcome: A clear table that tracks, for each frame, which object the blue dot was over (toy, face, screen, etc.).
7) 6_consolidation.py
Purpose: Merge the datasheet CSV (frame-level “What” and “Where”) with the corrected classification CSV (detections_summary_corrected.csv), adding participant metadata (infant/adult, age, etc.).
Process:
- Searches for
datasheetfolders andclassification-run-*directories withdetections_summary_corrected.csv. - Merges rows on the matching frame number, producing a combined CSV that includes both event labels and “What/Where” info.
- Inserts participant type and age columns.
Outcome: A final unified CSV for each participant that captures frame number, events, “What/Where,” and participant info.
8) 7_csv_correction.py
Purpose: A targeted script to fix specific mislabels in the consolidated CSV (for example, frames labeled (What='toy', Where='other') when they should be (What='man', Where='hands') under certain conditions).
Process:
- Identifies rows in the main CSV or datasheet CSV with known mislabeled events.
- Corrects them in place, ensuring no leftover incorrect tags.
Outcome: A final pass that cleans up any known, repeated labeling errors across multiple frames or participants.
9) 8_movie.py
Purpose: Combine everything into a final annotated video.
Process:
- Reads the final CSV data (participant metadata, “What/Where,” corrected events, etc.).
- Overlays text on each annotated frame (e.g., event names, participant type, frame number).
- Compiles all overlaid frames into a single .mp4 video.
Outcome: A clear, polished video that shows the original frames, detection overlays, and relevant text information for each participant. This is the ultimate deliverable for visual presentation.